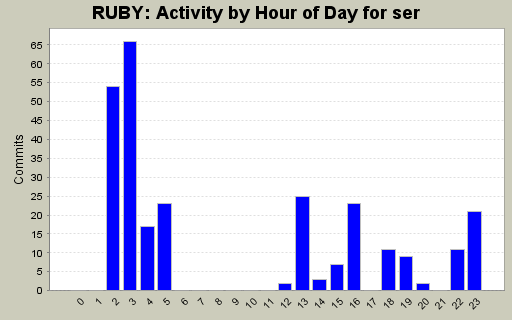
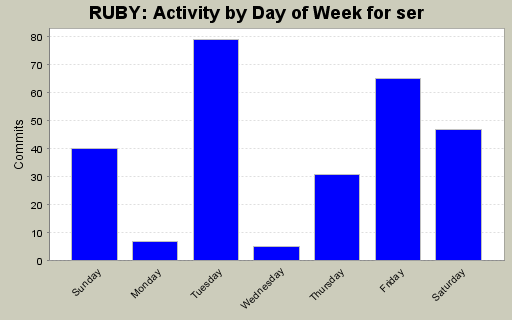
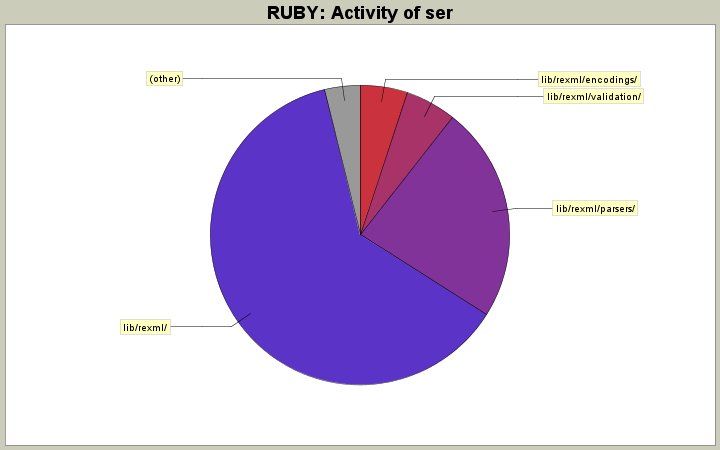
| Directory | Changes | Lines of Code | Lines per Change |
|---|---|---|---|
| Totals | 274 (100.0%) | 13204 (100.0%) | 48.1 |
| lib/rexml/ | 150 (54.7%) | 8221 (62.3%) | 54.8 |
| lib/rexml/parsers/ | 44 (16.1%) | 3080 (23.3%) | 70.0 |
| lib/rexml/validation/ | 4 (1.5%) | 724 (5.5%) | 181.0 |
| lib/rexml/encodings/ | 59 (21.5%) | 679 (5.1%) | 11.5 |
| lib/rexml/light/ | 4 (1.5%) | 267 (2.0%) | 66.7 |
| lib/rexml/dtd/ | 7 (2.6%) | 175 (1.3%) | 25.0 |
| / | 6 (2.2%) | 58 (0.4%) | 9.6 |
Merged from REXML main repository:
Fixes ticket:68.
NOTE that this involves an API change! Entity declarations in the doctype
now generate events that carry two, not one, arguments.
Implements ticket:15, using gwrite's suggestion. This allows Element to be
subclassed.
Two unrelated changes, because subversion is retarded and doesn't do
block-level commits:
1) Fixed a typo bug in previous change for ticket:15
2) Fixed namespaces handling in XPath and element.
***** Note that this is an API change!!! *****
Element.namespaces() now returns a hash of namespace mappings which are
relevant for that node.
Fixes a bug in multiple decodings
The changeset 1230:1231 was bad. The default behavior is *not* to use the
native REXML encodings by default, but rather to use ICONV by default. I know
that this will piss some people off, but defaulting to the pure Ruby version
isn't the correct solution, and it breaks other encodings, so I've reverted it.
* Fixes ticket:61 (xpath_parser)
* Fixes ticket:63 (UTF-16; UNILE decoding was bad)
* Cleans up some tests, removing opportunities for test corruption
* Improves parsing error messages a little
* Adds the ability to override the encoding detection in Source construction
* Fixes an edge case in Functions::string, where document nodes weren't
correctly converted
* Fixes Functions::string() for Element and Document nodes
* Fixes some problems in entity handling
Addresses ticket:66
Fixes ticket:71
Addresses ticket:78
NOTE: that this also fixes what is technically another bug in REXML. REXML's
XPath parser used to allow exponential notation in numbers. The XPath spec
is specific about what a number is, and scientific notation is not included.
Therefore, this has been fixed.
Cross-ported a fix for ticket:88 from CVS.
Fixes ticket:80
Documentation cleanup. Ticket:84
Applied Kou's fix for an un-trac'ed bug.
------------------------------------------------------------------------
142 lines of code changed in:
Merged changes into HEAD from REXML 3.1.5.
The list of bug fixes/enhancements is at:
http://www.germane-software.com/projects/rexml/query?status=closed&milestone=3.1.5
87 lines of code changed in:
Short summary:
This is a version bump to REXML 3.1.4 for Ruby HEAD. This change log is
identical to the log for the 1.8 branch.
It includes numerous bug fixes and is a pretty big patch, but is nonetheless
a minor revision bump, since the API hasn't changed.
For more information, see:
http:/www.germane-software.com/projects/rexml/milestone/3.1.4
For all tickets, see:
http://www.germane-software.com/projects/rexml/ticket/#
Where '#' is replaced with the ticket number.
Changelog:
* Fixed the documentation WRT the raw mode of text nodes (ticket #4)
* Fixes roundup ticket #43: substring-after bug.
* Fixed ticket #44, Element#xpath
* Patch submitted by an anonymous doner to allow parsing of Tempfiles. I was
hoping that, by now, that whole Source thing would have been changed to use
duck typing and avoid this sort of ticket... but in the meantime, the patch
has been applied.
* Fixes ticket:30, XPath default namespace bug. The fix was provided
by Lucas Nussbaum.
* Aliases #size to #length, as per zdennis's request.
* Fixes typo from previous commit
* Fixes ticket #32, preceding-sibling fails attempting delete_if on nil nodeset
* Merges a user-contributed patch for ticket #40
* Adds a forgotten-to-commit unit test for ticket #32
* Changes Date, Version, and Copyright to upper case, to avoid conflicts with
the Date class. All of the other changes in the altered files are because
Subversion doesn't allow block-level commits, like it should. English cased
Version and Copyright are aliased to the upper case versions, for partial
backward compatability.
* Resolves ticket #34, SAX parser change makes it impossible to parse IO feeds.
* Moves parser.source.position() to parser.position()
* Fixes ticket:48, repeated writes munging text content
* Fixes ticket:46, adding methods for accessing notation DTD information.
* Encodes some characters and removes a brokes link in the documentation
* Deals with carriage returns after XML declarations
* Improved doctype handling
* Whitespace handling changes
* Applies a patch by David Tardon, which (incidentally) fixes ticket:50
* Closes #26, allowing anything that walks like an IO to be a source.
* Ticket #31 - One unescape too many
This wasn't really a bug, per se... "value" always returns
a normalized string, and "value" is the method used to get
the text() of an element. However, entities have no meaning
in CDATA sections, so there's no justification for value
to be normalizing the content of CData objects. This behavior
has therefore been changed.
* Ticket #45 -- Now parses notation declarations in DTDs properly.
* Resolves ticket #49, Document.parse_stream returns ArgumentError
* Adds documentation to clarify how XMLDecl works, to avoid invalid bug reports.
* Addresses ticket #10, fixing the StreamParser API for DTDs.
* Fixes ticket #42, XPath node-set function 'name' fails with relative node
set parameter
* Good patch by Aaron to fix ticket #53: REXML ignoring unbalanced tags
at the end of a document.
1383 lines of code changed in:
Merged in development from the main REXML repository.
* Fixed bug #34, typo in xpath_parser.
* Previous fix, (include? -> includes?) was incorrect.
* Added another test for encoding
* Started AnyName support in RelaxNG
* Added Element#Attributes#to_a, so that it does something intelligent.
This was needed by XPath, for '@*'
* Fixed XPath so that @* works.
* Added xmlgrep to the bin/ directory. A little tool allowing you to grep
for XPaths in an XML document.
* Fixed a CDATA pretty-printing bug. (#39)
* Fixed a buffering bug in Source.rb that affected the SAX parser
This bug was related to how REXML determines the encoding of a file, and
evinced itself by hanging on input when using the SAX parser.
* The unit test for the previous patch. Forgot to commit it.
* Minor pretty printing fix.
* Applied Curt Sampson's optimization improvements
* Issue #9; 3.1.3: The SAX parser was not denormalizing entity references
in incoming text. All declared internal entities, as well as numeric
entities, should now be denormalized. There was a related bug in that the
SAX parser was actually double-encoding entities; this is also fixed.
* bin/* programs should now be executable. Setting bin apps to executable
* Issue 14; 3.1.3: DTD events are now all being passed by StreamParser
Some of the DTD events were not being passed through by the stream parser.
* #26: Element#add_element(nil) now raises an error Changed XPath searches so
that if a non-Hash is passed, an error is raised Fixed a spurrious undefined
method error in encoding. #29: XPath ordering bug fixed by Mark Williams.
Incidentally, Mark supplied a superlative bug report, including a full unit
test. Then he went ahead and fixed the bug. It doesn't get any better than
this, folks.
* Fixed a broken link. Thanks to Dick Davies for pointing it out. Added
functions courtesy of Michael Neumann <mneumann@xxxx.de>.
Example code to follow.
* Added Michael's sample code. Merged the changes in from branches/xpath_V
* Fixed preceding:: and following:: axis Fixed the ordering bug that Martin
Fowler reported.
* Uncommented some code commented for testing Applied Nobu's changes to the
Encoding infrastructure, which should fix potential threading issues.
* Added more tests, and the missing syncenumerator class. Fixed the
inheritance bug in the pull parser that James Britt found. Indentation
changes, and changed some exceptions to runtime
exceptions.
* Changes by Matz, mostly of indent -> indent_level, to avoid
function/variable naming conflicts
* Tabs -> spaces (whitespace)
Note the addition of syncenumerator.rb. This is a stopgap, until I can work on
the class enough to get it accepted as a replacement for the SyncEnumerator
that comes with the Generator class. My version is orders of magnitude faster
than the Generator SyncEnumerator, but is currently missing a couple of
features of the original. Eventually, I expect this class to migrate to
another part of the source tree.
1189 lines of code changed in:
Applied Nobu's patch to the XML document encoding structure in REXML. It
passes all of REXML's native tests as well as a couple of others, and should
fix potential threading issues.
98 lines of code changed in:
Merged in the changes from BSD bug report. shift-jis is now shift_jis, in
accordance with IANA
5 lines of code changed in:
r1025 | ser | 2004-07-18 08:18:36 -0400 (Sun, 18 Jul 2004) | 2 lines
@@ Fixed a CDATA pretty-printing bug. (#39) @@
r1026 | ser | 2004-07-18 09:03:02 -0400 (Sun, 18 Jul 2004) | 4 lines
@@ Fixed a buffering bug in Source.rb that affected the SAX parser @@
This bug was related to how REXML determines the encoding of a file, and
evinced itself by hanging on input when using the SAX parser.
r1028 | ser | 2004-07-18 09:06:18 -0400 (Sun, 18 Jul 2004) | 3 lines
* Minor pretty printing fix WRT CDATA segments.
@@ Applied Curt Sampson's optimization improvements @@
28 lines of code changed in:
These validation files for REXML need to be included in the main branch.
720 lines of code changed in:
r1002 | ser | 2004-06-07 07:45:53 -0400 (Mon, 07 Jun 2004) | 2 lines
* Workin' in the coal mine, goin' down, down, down...
r1003 | ser | 2004-06-08 22:24:08 -0400 (Tue, 08 Jun 2004) | 7 lines
* Entirely rewrote the validation code; the finite state machine, while cool,
didn't survive the encounter with Interleave. It was getting sort of hacky,
too. The new mechanism is less elegant, but is basically still a FSM, and is
more flexible without having to add hacks to extend it. Large chunks of the
FSM may be reusable in other validation mechanisms.
* Added interleave support
r1004 | ser | 2004-06-09 07:24:17 -0400 (Wed, 09 Jun 2004) | 2 lines
* Added suppert for mixed
r1005 | ser | 2004-06-09 08:01:33 -0400 (Wed, 09 Jun 2004) | 3 lines
* Added Kou's patch to normalize attribute values passed through the SAX2 and
Stream parsers.
r1006 | ser | 2004-06-09 08:12:35 -0400 (Wed, 09 Jun 2004) | 2 lines
* Applied Kou's preceding-sibling patch, which fixes the order of the axe results
r1009 | ser | 2004-06-20 11:02:55 -0400 (Sun, 20 Jun 2004) | 8 lines
* Redesigned and rewrote the RelaxNG code. It isn't elegant, but it works.
Particular problems encountered were interleave and ref. Interleave means I
can't use a clean FSM design, and ref means the dirty FSM design has to be modified
during validation. There's a lot of code that could be cleaned up in here.
However, I'm pretty sure that this design is reasonably fast and space efficient.
I'm not entirely convinced that it is correct; more tests are required.
* This version adds support for defines and refs.
r1011 | ser | 2004-06-20 11:20:07 -0400 (Sun, 20 Jun 2004) | 3 lines
* Removed debugging output from unit test
* Moved ">" in Element.inspect
r1014 | ser | 2004-06-20 11:40:30 -0400 (Sun, 20 Jun 2004) | 2 lines
* Minor big in missing includes for validation rules
r1023 | ser | 2004-07-03 08:57:34 -0400 (Sat, 03 Jul 2004) | 2 lines
* Fixed bug #34, typo in xpath_parser.
r1024 | ser | 2004-07-03 10:22:08 -0400 (Sat, 03 Jul 2004) | 9 lines
* Previous fix, (include? -> includes?) was incorrect.
* Added another test for encoding
* Started AnyName support in RelaxNG
* Added Element#Attributes#to_a, so that it does something intelligent.
This was needed by XPath, for '@*'
* Fixed XPath so that @* works.
23 lines of code changed in:
This is the log for the *previous* commit, but CVS is bloody stupid.
* Added XPath expansion and abbreviation to Parsers::XPathParser
* Improved the look of Element.inspect
* Added xpath() to Element and Attribute, allowing the generation of a unique
xpath for nodes of these types. This method for the other nodes still need to be
done
* Made REXML::XPathParser#match public
First pass at validation support. Minimal RelaxNG support.
* The tree parser is now an independant parser, like the rest.
* The first basic RelaxNG support is in. It supports elements, attributes,
choice, sequence, oneOrMany, zeroOrMany, and optional.
Improved support for converting XPaths to strings.
* XPath wasn't parsing ")" correctly.
Validation improvements:
* Fixed text
* Fixed attributes in choices
* Fixed text in choices. This change improves handling of all events that occur
without an end step (which is most of them).
* Fixed a bunch of cases
* Added support for <group>
* Added support for <value>
Workin' in the coal mine, goin' down, down, down...
* Entirely rewrote the validation code; the finite state machine, while cool,
didn't survive the encounter with Interleave. It was getting sort of hacky,
too. The new mechanism is less elegant, but is basically still a FSM, and is
more flexible without having to add hacks to extend it. Large chunks of the
FSM may be reusable in other validation mechanisms.
* Added interleave support
* Added suppert for mixed
* Added Kou's patch to normalize attribute values passed through the SAX2 and
Stream parsers.
* Applied Kou's preceding-sibling patch, which fixes the order of the axe results
90 lines of code changed in:
-
244 lines of code changed in:
Cross-ported fix for REXML bug #14, StreamParser and doctype events.
7 lines of code changed in:
------------------------------------------------------------------------
6 lines of code changed in:
------------------------------------------------------------------------
19 lines of code changed in:
Forgot to update the manifest with the new files :-/
2 lines of code changed in:
Added support for CP-1252 and ISO-8859-15 encodings for non-iconv systems.
167 lines of code changed in:
------------------------------------------------------------------------
923 lines of code changed in:
* Non-String attributes are now converted to Strings; this means code such as
elem.attributes["a"] = 1
will not cause an error when dumping the XML. It also means that:
elem.attributes["a"] # => "1", not 1
* Transitive indenting has been cleaned up.
* Fixed a potential bug in parsing non-ASCII encoded streams
* Fixed a bug where trying to fill in ParseException data was causing an
IO error (stream closed)
* Changes to Text mean that Element (and Text) can be used outside of a
Document context.
* In some rare cases, the base parser wasn't reading enough bytes from the
stream for the parsing algorithm to work properly. This has been fixed
(this was Ruby bug #48426)
49 lines of code changed in:
REXML CHANGES
The previous bug fixing the behavior of Element::text= introduced a bug that
occurred when calling (el.text = nil) to delete the first text node.
21 lines of code changed in:
* Fixed a bug in the evaluation of XPath's 'or'
* deprecated #type changed to class.name
* XPath's union was was being incorrectly interpreted
18 lines of code changed in:
(14 more)